If you have been using Python for some time, you likely already know the problem. Have you installed a Python package? Better yet, have you had to work out how to install a Python package? Well, you’re not alone.
Have you ever written Python code that runs fine on your machine, then handed it over to your colleague, and they responded that nothing works? This scenario has frustrated me for many years, and now, since I work at a company that uses open source, I can finally do something about it.
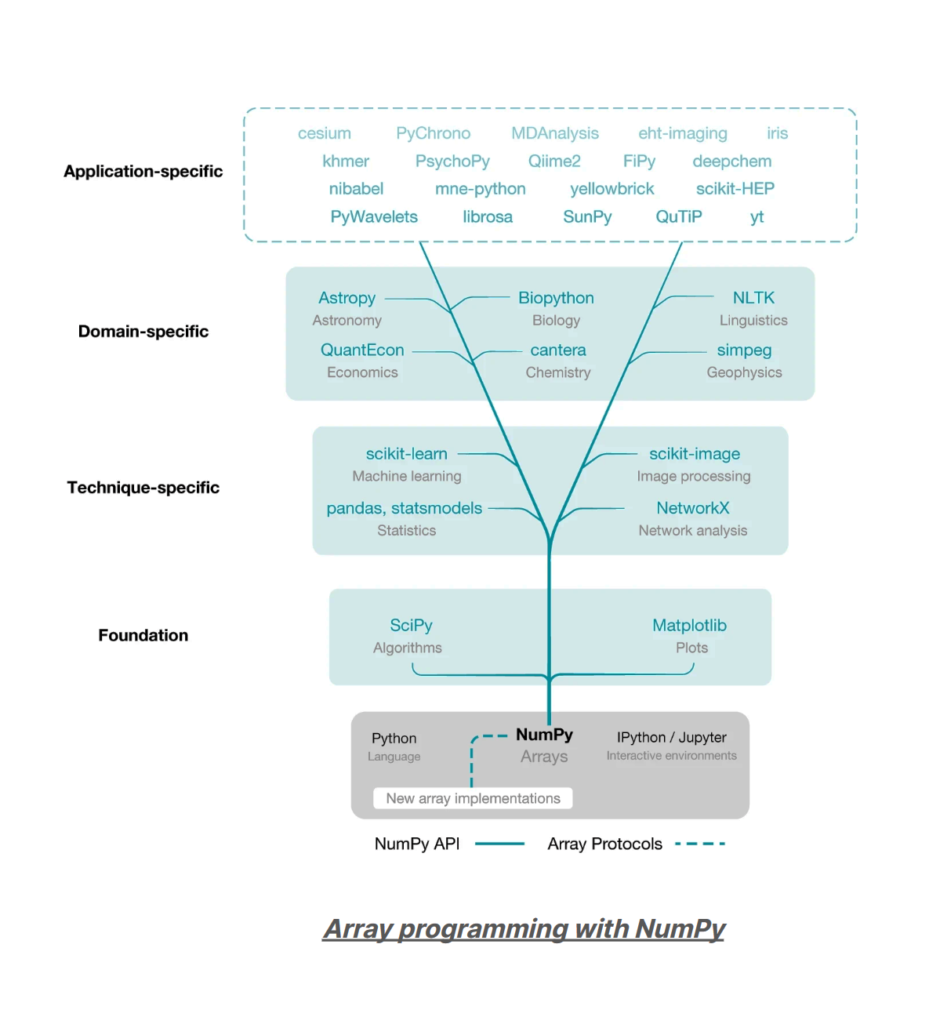
Today, we are benefactors of a massive community of libraries, which sounds great at first, but it’s the problem. When I started using Python in 2008, NumPy was the big thing. Now, NumPy is way down in the substructure—the basement, below the data science foundation.
Do you remember Sun Microsystems? We used to be able to take a binary from Solaris 1 and plop it into Solaris 8, and it would just work. You go from Panda’s 1.5 to 1.53, and maybe your stuff is okay, but use 2.0, and it ‘breaks.’ Backward compatibility is not a thing with Python (and there’s a reason for that). The cool new stuff coming out is amazing, but it has an issue.
Python is the bane of Enterprise IT. Software engineers want flexibility, the latest version of pandas and Polars, and the next version of PyTorch, which allows us to run our NumPy code on a GPU. We want that flexibility. We want to be able to do all that and more!
The flip side is that reproducibility becomes a problem. Here is typically what I’ve seen most people say/do:
We tend to agglomerate, or aggregate, these environments over time, which become this unholy thing that, if you push it slightly, will fall over. You, then, cannot recreate it because you did installations at various points in the past, and the state of the internet and available packages was different at those times. Even if I have the requirements.txt or the environment.yml conda, if I ran that six months ago and ran that same environment requirements.txt today, I will get a different set of packages.
We fixed this, right? We have containers in every IT department in the world.
Do you know how to write a Docker file? Did you enjoy learning how to write a Docker file, or would you be fine if you had never known such a thing existed? Yes, every IT Department, everywhere, insists, “Just write a Docker file,” but that’s only part of the solution.
We’ve seen that most organizations we consult with–their IT departments or their IT SysDev/DevOp groups—are used to something like Oracle. You upgrade Oracle once every three years. Maybe, if you’re aggressive, you apply a patch every six months or a security patch every month. They’re not used to data scientists saying, “Hey, [something] was released on Friday. Can I have it?”
They’re more likely to get the response of, “Okay. Fill out a change order. Get it signed by your manager. Get it signed by your manager’s manager, and then the manager’s manager’s manager will put it in the queue. It’ll go through our CI/CD system and verification security scan…” Then, in about eight months, it’ll be on the production Docker image you can use.
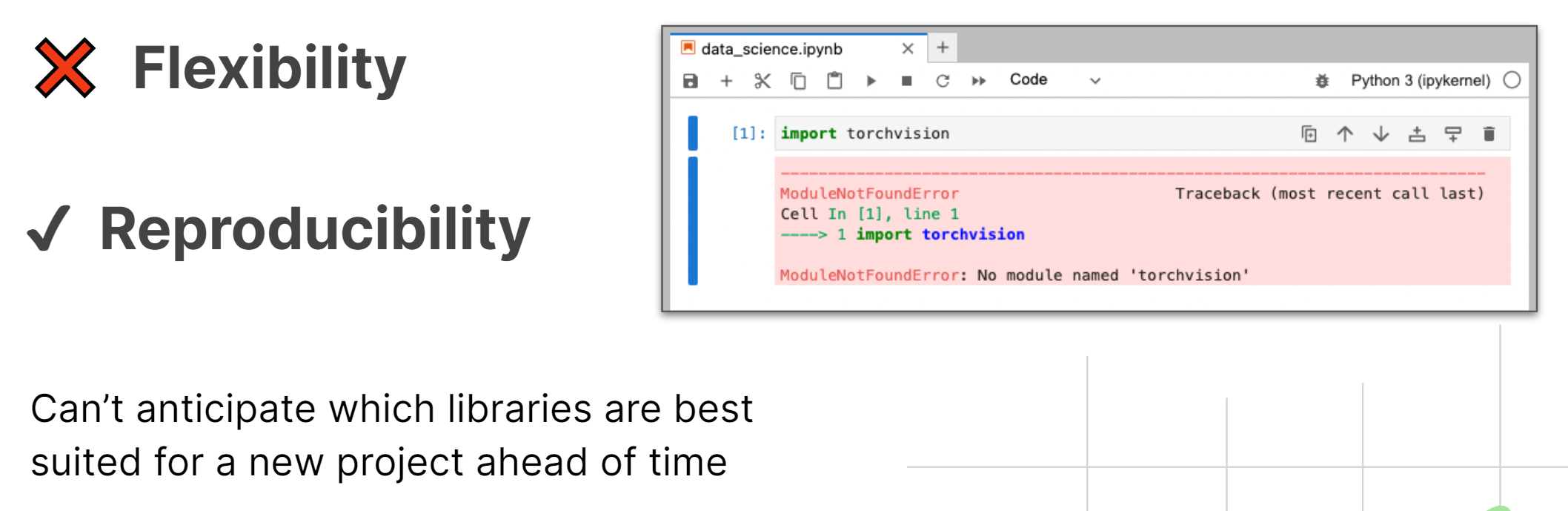
Have you ever started analyzing a new data set, and only after starting your project did you realize which packages you needed? Yeah, that’s the problem with the idea within companies that you can define all the software you need at the beginning of a project.
A couple of years ago, we analyzed traffic data for a client, such as how many people turn left at this intersection and other similar data. There’s a pandas extension that lets you identify routes. We didn’t know we needed that, but we needed to get it installed quickly and deployed. Most organizations need help transitioning this issue between wanting flexibility and reproducibility. Until now, you typically had to pick one or the other.
Best practices exist but are hard to learn and use consistently. For starters, always use an environment specification. Like many teams, we learned this the hard way. We were doing a project for a company around recognizing brand images in videos. For example, if you see a Chase logo while watching a video, you want the system to say, “Oh, the Chase logo is in this video.” We found a good model built about eight months before the project, and they published the requirements.txt. However, it took us two weeks to get a working environment because, in those eight months, so many of the packages they depended on had changed. Even though they pinned some packages, some dependencies still changed.
Once you have an environment specification, install your environment and create a lock-file. A lock-file is the exact list of every package installed because you have that requirements.txt, including the hash, the architecture, and all that kind of stuff.
Now, you have an environment and suddenly realize you’re using pandas, but all your data is in Parque. To fix this, you install PyArrow, go back, put it in your environment specification, and make a new environment. That is the safest way to recreate environments. Of course, there are more best practices. If you do some of these things, you can have reasonable reproducibility, but doing this consistently and remembering to do it all the time has required extra steps.
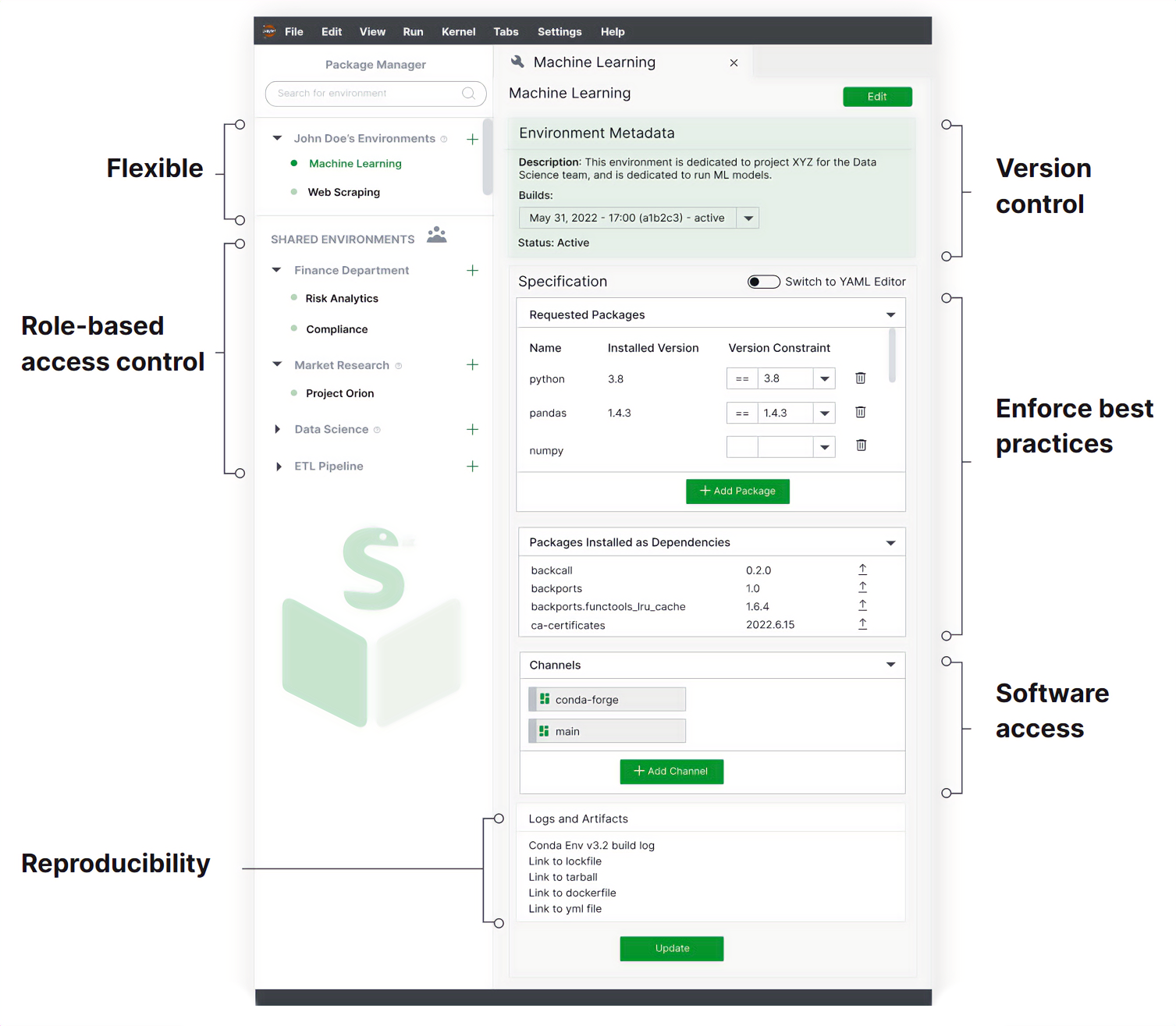
We’ve taken some of the existing best practices for the conda ecosystem. We’re going from, “You tell us what you want, and we will make sure we follow all the best practices under the hood and give you an environment that’s reproducible, that you can transfer other people, etc.” All that, and an interactive graphical user interface.
The conda-store UI tries to force you to use best practices. You give it an environment name, define your specification, and then it lists items installed as dependencies. It lists where it’s coming from and automatically creates a lock-file, a Docker image, and a TarGZ (you can unpack somewhere else). You’re divorcing your specification from the artifact. The artifact is an environment; you might want to run it locally, you might want to run it in the cloud, and you might want to ship it to someone else’s machine. We want those to be two separate issues.
In the live demo, I started with the cloud-hosted version of conda-store, which includes some features that are not yet available on the desktop version. In the cloud-hosted setup, I have spaces and environments that I own, allowing me to edit, change, and add new environments.
I began by creating a Python environment within a specific namespace or group. In this namespace, both my colleague and I had edit rights, while others with access to the PyCon 2023 group had read-only rights. This setup exemplifies how conda-store can be used in a corporate setting to manage role-based access to environments, enabling secure editing and sharing.
Next, I switched to the local version running on my laptop. With several environments already set up, I demonstrated how to create a new one, specifying that it should come from conda-forge rather than the default channel. The intuitive UI simplifies this process; when I hit the create button, it builds the environment, generates artifacts, and creates a lock-file in the background.
One of our upcoming features, expected to be released in a few months, is the “Build for All Platforms” option. Currently, the cloud version builds for Linux, while my local version builds for OS X. Soon, a checkbox will allow you to develop equivalent environments for Mac OS X and Windows, enhancing cross-platform compatibility.
Full disclosure: I have a habit of breaking environments. However, with conda-store, I can easily revert to previous versions thanks to its comprehensive logging of fully versioned environments. For instance, I intentionally broke my environment during an experiment, but it wasn’t a problem because I could simply revert to a previous, functional version.
In my demo, I demonstrated this with an active environment containing Torchvision, PyTorch, and pandas. If I want to return to a version without pandas, I can click edit, change the environment version, and create a new active environment. Conda-store allows me to effortlessly switch between versions of my environment from three or six months ago without the hassle of reinstalling from an outdated YAML file that might not work.
We have been using conda-store in production with multiple companies in the cloud, particularly in data science platforms and JupyterHub settings, for about 2-3 years. The compatibility between the desktop version and Mac and Windows compatibility is near the bleeding edge. While it is now available for desktop use, it still needs to be more production-ready before a full launch. Nevertheless, we encourage you to try it out!
Having dealt with packaging and environments for years, I believe we shouldn’t have to worry about these issues. We should be able to install and share packages without encountering the “Well, it works on my computer” problem.
This project is now part of the conda incubator, so it’s something we built and submitted, and it’s on its way to becoming an official part of conda through the incubator program. We would love for you to use it, provide feedback, and help us develop it further. Quansight is a consulting company. If you are annoyed about how your organization or group deals with environments, we’re here to help with packaging and building systems like this.