

This article, developed from a 2024 PyData NYC presentation of the same title, written with help from Marco Gorelli, explores the strengths and limitations of these DataFrame library tools, their compatibility with existing workflows, and how they can be integrated into modern data pipelines. We’ll also discuss Narwhals, a lightweight library designed by Marco to bridge compatibility between pandas, Polars, and more.
Whether you’re working with datasets in the tens of gigabytes (or more), experimenting with new technologies, or simply looking for better ways to work, this guide will help you navigate the growing ecosystem of DataFrame tools. By the end, you’ll have a clearer picture of which tool fits your needs and why.
For a deeper dive into these topics, check out Marco’s post, The Polars vs pandas difference nobody is talking about on the Quansight Labs blog.
I started using Python when I moved from MATLAB to Python in 2008. During my early career there, pandas did not exist. I remember at probably SciPy 2010 or so—almost 15 years ago—there was a Birds of a Feather session where everyone got in the room to discuss many of the problems associated with building a DataFrame library or labeled arrays, as they were then referred to. There was this big discussion about possible approaches and all the things one should and shouldn’t do when building labeled arrays. Fast forward a year, and Wes McKinney, who was in that previous meeting, comes back introducing pandas, ignoring many things everyone said we shouldn’t do when building labeled arrays in favor of a working implementation. The rest is history, and pandas is by far the most popular DataFrame library in existence.
DataFrames are at the heart of modern data analysis, and for many, pandas is the tool that started it all. Over the years, it has become synonymous with data manipulation, offering flexibility, domain-specific libraries, and unparalleled ecosystem support. However, as data sizes grow and performance demands change, new tools have emerged to challenge pandas’ dominance, each bringing unique strengths to the table.
Polars and DuckDB are two such tools, each designed to solve specific pain points that pandas can struggle with. Whether handling massive datasets efficiently, optimizing query performance, or introducing innovative syntax, these tools offer exciting new possibilities for data professionals. Yet, choosing the right tool is not always straightforward. Each has its learning curve, trade-offs, and ideal use cases. Polars introduces a new syntax designed for flexibility and performance, while DuckDB reimagines SQL for modern analytical workflows. Meanwhile, pandas remains a solid choice for most workflows, especially when stability and library compatibility are top priorities.

For many data professionals, pandas is the first tool they reach for when working with structured data. It has earned its reputation as the backbone of data science workflows thanks to its flexibility, extensive documentation, and compatibility with domain-specific libraries like GeoPandas and Cyberpandas. With over a decade of development, pandas has become a cornerstone of the Python ecosystem, offering a stable and consistent API that millions of users rely on daily.
Pandas excels in its breadth and reliability. Its extensive support for data manipulation tasks, seamless integration with Python libraries, and wide adoption in the data science community make it an incredibly versatile tool. Whether you’re working with time-series data, categorical variables, or complex types like sparse or periodic data, pandas likely has a solution.
Moreover, pandas is supported by a robust ecosystem of libraries, ensuring that you’ll rarely face a task it cannot handle. Its plotting integrations, machine learning compatibility, and domain-specific extensions have made it the go-to solution for everything from quick data exploration to building production-grade pipelines.
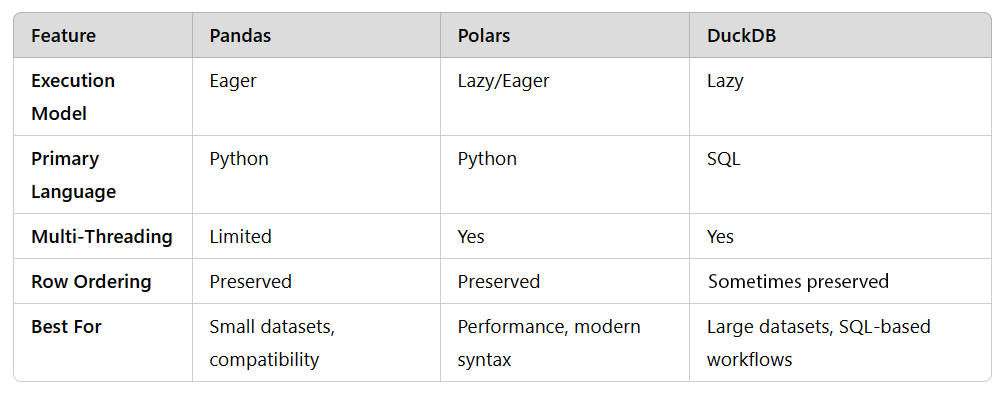
However, pandas is not without its challenges. One of the most common complaints is its performance when working with large datasets. For example, processing a 50 GB file on a laptop can often result in memory errors or crashes. Pandas was designed as an eager execution library, meaning operations are executed immediately rather than optimized in batches. This approach can lead to inefficiencies when dealing with large-scale data.
Another challenge lies in its API. While powerful, pandas’ API can be overwhelming and occasionally unintuitive. Features like multi-indexing and hierarchical tables are incredibly flexible but can introduce complexity that’s difficult to manage, especially for new users.
Despite its limitations, pandas remains a vital tool for many workflows. It provides a level of stability and compatibility that is unmatched by newer tools. The maintainers are cautious about introducing breaking changes, ensuring that code written years ago still works today. Additionally, efforts like the PyArrow backend allow pandas to leverage modern technologies, offering a bridge to more performant frameworks.
For most small to medium-sized datasets, pandas continues to be an excellent choice. Its familiarity, flexibility, and ecosystem support make it a safe and reliable option for a wide range of use cases. However, for larger datasets or performance-critical workflows, it’s worth exploring complementary tools like Polars and DuckDB. (Note: in this discussion, we are focusing on single-node performance; for distributed multi-node performance, there are excellent tools like Dask – See: https://docs.coiled.io/blog/tpch.html for a discussion of scaling from 100GB to 10TB datasets)

As data grows in size and complexity, traditional tools like pandas can struggle to keep up. This is where Polars steps in. Designed for speed, flexibility, and modern data workflows, Polars reimagines the DataFrame paradigm with a focus on lazy execution, memory efficiency, and innovative syntax.
Polars is built from the ground up with performance in mind. Unlike pandas, which processes operations immediately (eager execution), Polars supports both eager and lazy execution. Lazy execution allows Polars to optimize operations before running them, reducing memory usage and improving efficiency. This makes it particularly well-suited for workflows involving medium to large datasets.
One standout feature of Polars is its ability to handle operations on sorted data intelligently. Once you sort your data, Polars remembers the order, enabling faster subsequent operations. It also shines in window functions, which are both fast and intuitive to implement.
While many tools mimic pandas’ syntax for ease of adoption, Polars takes a different approach. It introduces its own syntax, designed to be more expressive and optimized for modern data workflows. This might seem daunting at first, especially for users familiar with pandas. However, once you understand how Polars’ expression-based system works, it often feels more intuitive and scalable than pandas’ approach.
People seem to move to Polars because of performance, but the reason you stay is the syntax. As someone who has used pandas for a very long time—about 15 years since it came out—and who only recently started playing around with Polars, I have to say I have fallen in love with its expression system. It takes a little while to get your head around it, but it’s very composable and generalizable.
Polars leverages Apache Arrow as its memory format, providing a foundation for efficient memory handling and compatibility with other Arrow-based tools. Arrow’s inclusion also simplifies working with external libraries and enables zero-copy operations where possible, reducing overhead when transitioning between tools.
Polars is inherently multi-threaded, which allows it to utilize modern multi-core processors effectively. Unlike pandas, which is largely single-threaded unless paired with external tools like Dask, Polars provides parallelism out of the box. This significantly boosts performance for compute-intensive tasks.
While Polars does not (yet?) support all of pandas’ complex data types (such as sparse or period), it also has excellent support for data types such as fixed and variable-length lists, structs, as well as state-of-the-art strings. Recent developments, including its CUDA integration for GPU acceleration, promise even greater performance for computationally heavy workflows.
Polars is an excellent choice for:

Unlike traditional databases, DuckDB is an in-process system, meaning it doesn’t require a server. It works directly within your Python environment or notebook, offering the power of a full analytical database without the overhead. For example, DuckDB can process a 50 GB dataset on a laptop, even when decompressed to 150–200 GB, by streaming data through memory instead of loading it all at once.
SQL-Based Querying
Handling Large Datasets
DuckDB excels in:
However, DuckDB’s SQL-first approach can feel limiting for users who prefer Python-based tools. Its Python API is functional but not as well-documented or intuitive as pandas or Polars. Additionally, some operations, like window functions or cumulative sums, require explicit ordering clauses (`ORDER BY`) due to limited guarantees of row ordering in query results.
When it comes to performance, both DuckDB and Polars offer unique strengths that make them stand out from traditional tools like pandas. However, their design philosophies and execution models cater to different needs, making them complementary rather than direct competitors.
DuckDB truly shines at larger scales, thanks to its efficient streaming engine. It excels in handling massive datasets, such as those in the range of 1 TB to 10 TB. Benchmarks, like those conducted by Coiled, show DuckDB’s impressive performance across industry-standard TPC-H queries. While few users regularly work with datasets this large, it’s common to encounter data in the 50–500 GB range—and both DuckDB and Polars handle these workloads effectively.
Polars, on the other hand, delivers exceptional performance for smaller to medium-sized datasets. Its ability to execute operations lazily or eagerly provides users with flexibility depending on their workflow needs. Polars also stands out in tasks like window operations, where its optimized memory handling and sorting capabilities give it an edge.
A key difference between these tools lies in their execution models:
Both tools handle datasets larger than your machine’s memory by streaming data through memory rather than loading it all at once. For example, decompressing a 50 GB Parquet file might expand to 150–200 GB in RAM—well beyond the limits of most laptops. DuckDB and Polars efficiently process these datasets without crashing, making them invaluable for data professionals without access to clusters. Note that Polars’ streaming engine is still experimental, but a full-rewrite is underway.
In many workflows, these tools complement rather than replace each other. For example, you might use DuckDB for initial data extraction and processing, then transition to Polars or pandas for detailed analysis and visualization. Both DuckDB and Polars allow for seamless integration, enabling smooth transitions between tools.
By experimenting with these tools on real-world projects, you can discover their strengths and limitations, ensuring you’re prepared for any data challenge. There’s space for all three tools—pandas, Polars, and DuckDB—to coexist, depending on your needs. The growing diversity of DataFrame tools has introduced exciting possibilities for data professionals. Pandas, Polars, and DuckDB each bring unique strengths to the table, but they aren’t mutually exclusive. Instead, they complement one another, enabling seamless transitions and interoperability across workflows.
These advancements aren’t about replacing pandas but complementing it. By combining tools, data professionals can build workflows that leverage the unique strengths of each. For example:
Thanks to ongoing collaboration in the data science community, these tools are becoming increasingly interoperable. For example, you can:
This interoperability ensures that data professionals can choose the best tool for each stage of their workflow without being locked into a single solution.
Polars has gained traction for its speed and flexibility, offering advanced features like lazy execution and multi-threading. One of its early challenges—compatibility with upstream and downstream libraries—is steadily improving.
DuckDB is revolutionizing how we think about analytical workflows. Its ability to handle massive datasets efficiently, combined with SQL’s stability as a language, makes it a powerful choice for both preprocessing and integration with other tools. DuckDB’s support for pandas and Polars further cements its role as a key player in modern data workflows.
For library maintainers, tools like Narwhals are pushing the boundaries of compatibility. Narwhals provides a lightweight, dependency-free way to integrate support for multiple DataFrame libraries, enabling seamless transitions between pandas, Polars, DuckDB, and others. For instance, Altair’s ability to work with Polars is powered by Narwhals under the hood. While not an end-user tool, Narwhals is a valuable asset for developers creating tools that need to operate across multiple libraries.
The availability of these new tools is essential for many data professionals. Previously, handling large datasets can require specialized hardware or clusters. With DuckDB and Polars, datasets that once crashed machines can now be processed efficiently on laptops. Polars’ recent CUDA integration adds GPU acceleration to the mix, promising even greater performance for computationally intensive tasks.
This ability to integrate tools seamlessly ensures that users can adapt their workflows as their needs evolve.

For those starting new projects, now is the perfect time to explore these tools. Try Polars or DuckDB for smaller analyses, or incorporate them into larger workflows to see how they perform in real-world scenarios. Each tool brings unique capabilities to the table, and the investment in learning them can pay off significantly.
Pandas is still awesome—it’s everywhere, and this is not about criticizing pandas. However, having new tools like DuckDB and Polars in the ecosystem makes everything better. While these tools require an investment in learning new syntax, they provide more choices and enable work with much larger datasets.
As the ecosystem grows, the tools we use are becoming more powerful and adaptable, enabling us to solve bigger problems with fewer constraints. By experimenting, learning, and integrating these tools into your workflows, you’re not just keeping up with the evolution of data science—you’re helping to shape its future. If you’re a tool builder looking to support multiple libraries, consider using Narwhals.
The tools we’ve explored—pandas, Polars, and DuckDB—represent the cutting-edge of DataFrame libraries, but even the best tools are only as effective as how you use them. Are you confident you’re getting the most out of your current workflows? Could exploring these tools unlock new efficiencies or capabilities for your projects?
What’s the biggest problem you’re facing with your data workflows today? If you’re ready to move past limits, I’d love to hear from you. Whether you’re navigating the challenges of integrating these tools, tackling datasets that push your current systems to the edge, or simply wondering which tool is right for your next big project, let’s talk. Drop me a message or reach out to the Quansight team.
Together, we can explore how to optimize your approach, streamline your analysis, and take your work to the next level.



