Generative AI is everywhere, and if one thing’s clear by now, it’s this: These models aren’t going away any time soon. Sorting marketing hype from actual technology can lead to disillusionment and skepticism. These aren’t ‘magic thinking machines’… And yet, they are still incredibly useful when used well. So, what are some essential things to keep in mind when you’re dealing with this evolving technology? Let’s break it down.
Are LLMs ‘Just’ Next-Token Predictors?
Yes. Yes, they are. Can we all go home now?
…Not quite.
It’s true that at the core of most modern LLMs lies a very simple pattern: Given the previous context, generate a prediction for the next most likely partial word (or token). And, because these models can do this so amazingly well, it may be tempting to attribute Understanding to them (with a capital U!). They sound like they understand, but it’s important to remember that they’re generating responses based on statistical probabilities, not “genuine comprehension.” Seeing where they fail can almost feel like pulling back the curtain on a grand deception – “They don’t actually think! That thing can’t even count the number of Rs in Strawberry!”
That realization is important because it helps us sort through what these models are and what they are not. Importantly, just because they aren’t “actually intelligent” doesn’t mean they aren’t actually helpful. LLMs, like calculators or Python scripts, are tools. Knowing why GPT-4 “couldn’t count the number of Rs in ‘Strawberry’” is like understanding why a computer “can’t even add two numbers together.” If you were to launch Python and simply run 0.1 + 0.2, the answer would likely be 0.30000000000000004: A floating-point error, and one that programmers will have expected and worked around. And rather than say, “this thing can’t even do math!” we recognize this as a limitation of the technology and adapt our patterns around it.
LLMs Only Know Encoded Vectors
Every LLM encodes text differently (tokenization!), so the same phrase in one model may not be the same vector in another. But in general, most modern LLMs are decoder-only models that start from text-string -> tensor, and that tensor gets fed into the model.
Tokenization Changes With Context
And sometimes, even within the same model, tokenization of a word shifts depending on the surrounding content.
Fun, right?
The key here is to remember how information is encoded: the model never ‘sees’ the letters in the word. It may have learned some things about that particular token, or tokens, based on how they’re used in other places during training, but it has no way to actually ‘read’ the letters. At this point, the ‘Strawberry’ question has become enough of a running joke that most modern LLMs will have had this specifically trained in: Google’s Gemma3-27B was just released, and it gets it just right… But a followup, “How many Rs in Harmonica” came back declaring two.. *Hrm*. Convert it to ‘h a r m o n i c a,’ and it can not only correctly count the number (1) but also tell you it’s in the 3rd spot.
Base Models vs. ‘Instruct’ Tuning
A ‘base model’ is specifically trained to continue the current presented pattern: Pass in the start of a poem and it continues that poem.
What finally turns ‘GPT-3’ into ‘ChatGPT’ is instruct tuning. This is when further training is specifically done to teach the model how to respond to prompts like a conversation. With these models, you can ask questions, and the model has been trained to understand what that means. This training typically follows a rigorous template with specialized tokens used to delineate sections..
For example, Microsoft’s Phi-4 prompt template:
<|im_start|>system<|im_sep|>
You are a medieval knight who must provide explanations to modern people.<|im_end|>
<|im_start|>user<|im_sep|>
How should I explain the Internet?<|im_end|>
<|im_start|>assistant<|im_sep|>
Behind the scenes, a similar template helps guide responses in GPT-4o, Claude, LLaMA, etc. Strict adherence to these templates ensures the model behaves as expected. If you’re trying to run something and the replies don’t make a lot of sense, one of the first places to check is the integrity of your prompting template: an added space or new-line character can be enough to throw some models completely off.
What’s With Quantization?
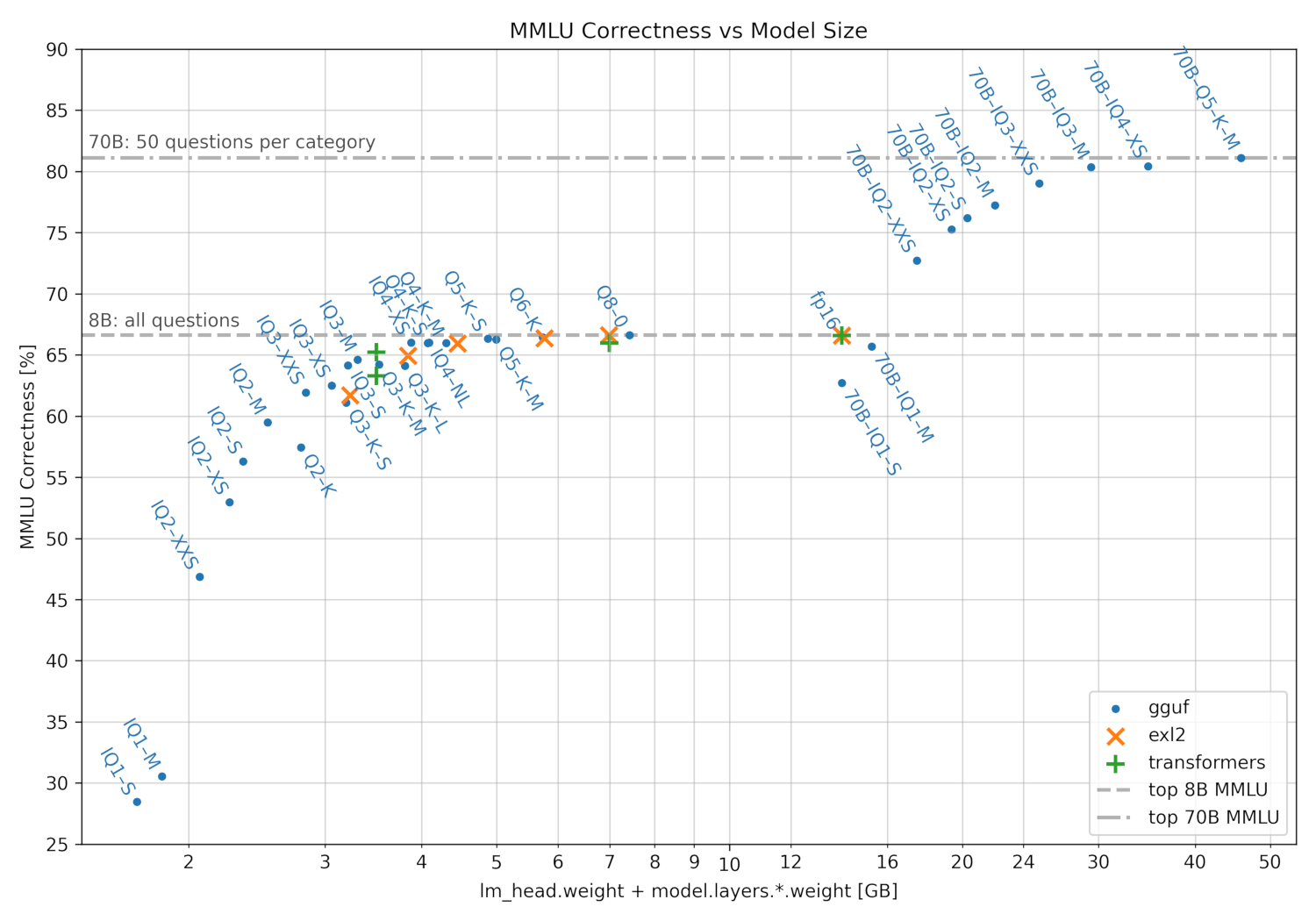
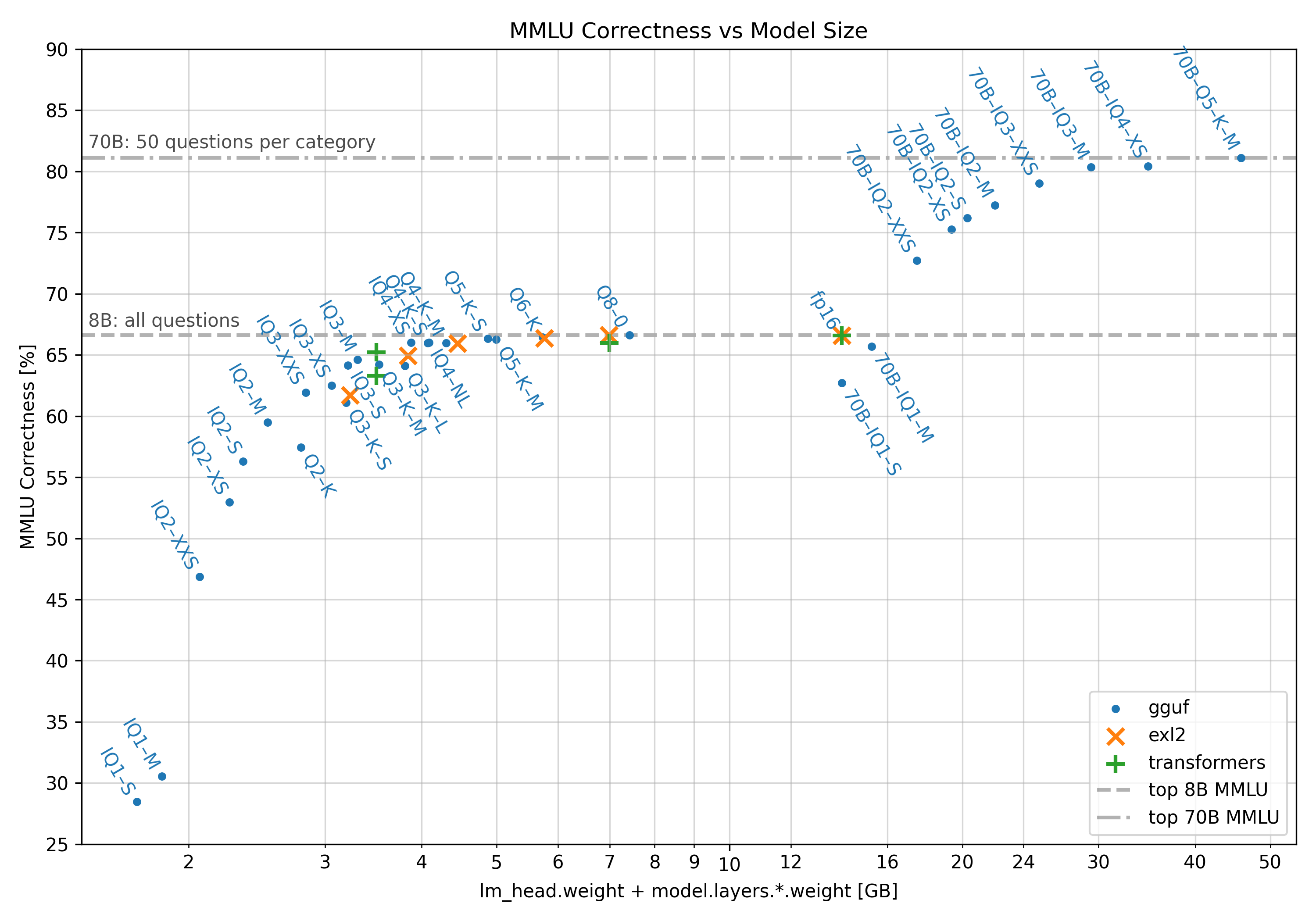
Ever heard of GPTQ, AWQ, EXL2, or GGUF? These are different quantization formats that take full-precision models and intelligently scale their weights into lower-precision values to save memory while preserving performance. Not every model weight is created equally – the quantization routines will keep some at full precision while others get converted to a low-precision equivalent. In this community-created plot, you can see a number of different quantization routines and their relative impact on a performance metric. The markers with Q4 in their name are roughly 30% the size of the original weights, while having lost very little of the original model’s performance.
Generally speaking, larger models suffer relatively less from quantization than smaller models, where the sheer number of parameters helps preserve performance. However, some newer models are getting much longer pretraining, stuffing more and more nuance into their weights across trillions of training tokens. These models may suffer performance degradation more quickly than older models.
Depending on your needs, you will often see better performance running a high parameter, quantized model than you would by trying to fit a smaller model at full precision in your available memory. As a slight exception, code generation applications tend to see the quality of output fall more on quantization because of the specific nature of programming languages.
The ‘Context Window’ Problem
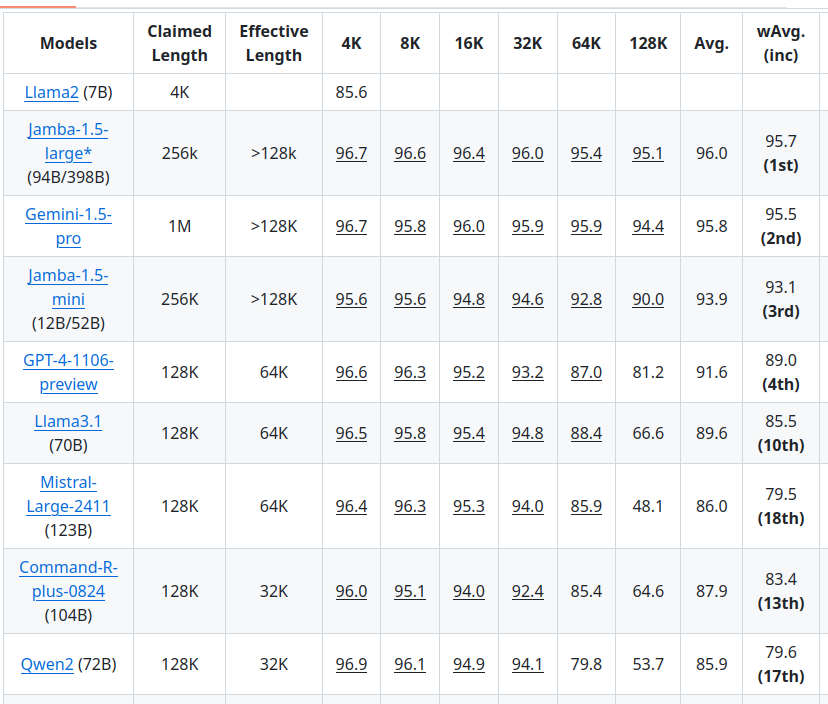
Most modern LLMs are based on transformers; these deep learning mainstays are masterful at understanding patterns and sequences. However, they come with a cost: The longer the sequence going in (the “context”), the more memory the model needs to use that information. The architecture of the model and the training that it went through will roughly determine the maximum length input that it can handle, but not all models ‘see’ perfectly well across that entire range. Below is an excerpt from the NVIDIA RULER benchmark that roughly equates to how well the model ‘sees’ information across a given context length. Keep in mind that the required memory to load the entire context window may sometimes be much greater than even the model weights themselves.
Machine Learning researchers are continually working on tricks for making models work more efficiently and across longer lengths. One of the earlier success stories in length extension was RoPE (rotary position embedding) scaling.
Early in the post-ChatGPT world, folks figured out you could improve the final results of an LLM’s output by asking it to ‘Think Step by Step.’ But with the recent rise of models like OpenAI’s o1/o3, Deepseek R1, Qwen QwQ, and others, it’s clear that training in these patterns and reinforcing what they do provides significantly more in the way of ‘reasoning’ improvement. “But I thought you just said these things don’t think?!” They still don’t, and in fact, the chains of reasoning that get produced don’t necessarily have to be cogent ‘reasoning’ – it’s more of a ‘mulling it over’ phase than strict, hard ‘logic’ that would please a philosophy professor. However, it still helps the models improve their results.
Some fun facts:
These models perform better at reasoning-heavy tasks but won’t magically improve everything.
They can “reason” in latent space (yep, we’re deep in AI-nerd land now). See research here.
Test-time compute is expensive! If you need structured thinking, use a reasoning model. If you need fast, reliable output, stick to a basic model.
‘Reasoning’ can even happen in short-hand and still provide performance lifts. Yet more papers!
LLMs can generate a lot of interesting content on their own, but they work best when embedded into larger applications. Generated code execution, external resource retrieval (RAG), tools, and ‘actions’ are all parts of what can allow your LLMs to reach the next level in usefulness, but they need careful integration.
‘Agents,’ as a notion, are En Vogue, the idea that you set a task to ‘an LLM’ and it carries out your needs. Still, there’s danger in anthropomorphizing the model itself, as well as oversimplifying the pieces that go into allowing that ‘Agent’ to function. Currently, it may be more accurate to think in terms of workflows and pipelines and to recognize that high-performance systems still need significant amounts of tuning around the application and the LLM.
LLMs Are Not Like Code (But Also, They Kind of Are)
Using LLMs effectively is its own art form. You wouldn’t use Pandas to train a neural network, and you shouldn’t expect an LLM to handle tasks that don’t fit. Knowing where an LLM will help – or hinder – is half the battle.
That’s it! Now you know what your parents didn’t teach you about GenAI (unless your parents are AI researchers, in which case, lucky you).


![A code snippet shows how a text string, "How are you doing today?", is encoded into a tensor of integers using a tokenizer. The code first assigns the result of encoding the string to the variable input_ids. Then, the value of input_ids is printed, showing the tensor tensor([[7801, 1584, 1636, 6965, 9406, 1063]]).](https://quansight.com/wp-content/uploads/2025/03/GenAI1.png)

![The image shows a code snippet where the question "How many letter Rs are in the word Strawberry?" is encoded using a tokenizer. The output is a tensor of integers: tensor([[ 7801, 3325, 10679, 76560, 1584, 1294, 1278, 3541, 121509, 33681, 1063]]). This indicates that the tokenizer has converted each word and punctuation mark in the question into a corresponding numerical ID. For example, "How" is represented by 7801, "many" by 3325, and so on. The word "Strawberry" is encoded as 33681. The question mark is encoded as 1063.](https://quansight.com/wp-content/uploads/2025/03/GenAI3.png)




{kind=link}