
What we built originally started as a demo we had hoped to showcase in Austin back in March, but it didn’t quite fit the format. As it turns out, a blog post is probably a better medium for this anyway.
The project draws on a general pattern that’s been gaining traction lately—a deeper exploration of local, document-based research workflows—what people call “deep research.” It’s not entirely new, but it recently got more attention when OpenAI released it as an official mode, which encouraged others to follow suit. In their model, deep research roughly means: given a question, the system goes out to the internet, scrapes a bunch of relevant information, refines the questions, collects more content, and builds a report from all that. You could ask it, “Tell me about all the recent congressional hearings on a topic,” and it’ll try to fetch everything, collate it, and generate a summary.
That pattern generally relies on a web agent to gather information and an LLM to summarize and extract key points. The output can be hit or miss—you’re rolling the dice—but it’s often good enough for a first pass. That’s how I view a lot of these tools: they’re not perfect, but they’re excellent 80% solutions that help you get started and think through a problem.
So, I built a similar pattern with one major difference: no internet. Instead, we focus entirely on local documents. Well, ok, I had to go get a bunch of interesting PDFs first, but many groups will already have these just sitting around. Imagine you’re a large enterprise customer with a trove of internal documentation. The idea is that the user comes in, poses a question, and the system runs out and pulls in relevant information from those local sources.
The overarching goal here is local deep research. Everything runs locally on a 24-gigabyte GPU. It’s a powerful little machine, but it’s still something you could reasonably run at home. As a side note, I somehow ended up with 1,852 open tabs on my phone, just squirreling away interesting things to check out later. For this project, I exported all of those as a CSV and ran them through an LLM to extract interesting URLs related to the topic.
“...part of the process is figuring out how to use your resources efficiently. This can be as much an art form as a technical challenge.”
Dillon Roach
A technical aside here: part of the process is figuring out how to use your resources efficiently. This can be as much an art form as a technical challenge. If you ask a model to evaluate URLs one by one, it might take 10 minutes, even with a batch queuing system set up. But if you group six questions per inference request, this allows the system to spend more time where it’s most efficient: in batch inference mode. Instead of asking questions serially, which ends quickly and costs in pre-processing overheads, grouped+batched queries let you compress the task into two minutes instead of ten.
That kind of efficiency matters—especially at scale. If you’re an enterprise, time spent querying is GPU time, and GPU time is money. So, how you build and orchestrate these systems can have real implications on cost.
After processing the initial batch, I took a bit of a shortcut. Rather than running the full cycle every time, I selected 50 archive links and pulled down the PDFs directly. The goal was to show something concrete, and grabbing a representative slice made things a little more manageable.
Once I had those PDFs, I needed to run OCR on them; a constant and necessary challenge familiar to many in the office – Optical Character Recognition for the fortunate uninitiated. The OCR system I used was an open source model+code built by Allen AI—they’re a particularly open and collaborative research group. What stands out about them is that when they release a language model, they include not just the weights but also the code and the data used to train it. It’s truly open, in contrast to many others who claim to open source a model but leave it unreproducible. So, I wanted to highlight Allen AI for that—they’re doing it right. Their tool extracts text from PDFs so that we can actually use it downstream in the pipeline.
That said, no PDF extraction tool is perfect—not even close. Benchmarks tend to land between 70% and 90% accuracy. If you’re paying for top-of-the-line services, maybe you’ll see low 90s. But even then, nobody’s hitting 100%. In fact, some proprietary services still deliver 50–65%, which can be worse than open-source tools in many cases.
We ran into this exact problem with a client who had an open source module they were using to convert a huge number of internal PDFs into searchable, indexed content for their retrieval-augmented generation (RAG) pipeline. The extraction process just didn’t hold up and left the pipeline with duplications and gibberish that would be a later headache in cleanup.
If you want to do this kind of work locally—without paying for something like Azure’s highest-benchmark services—you do have options. Tools like Mistal’s extractor are solid. There’s also a set of newer Chinese models that just came out and perform slightly better, Qwen2.5-VL. But in general, this step is a known bottleneck in the pipeline. It’s a quirky crux in an otherwise smooth process. For an OCR benchmarking deep dive, check out a recent post over at OmniAI: https://getomni.ai/ocr-benchmark – No benchmark is perfect, but it gives a solid idea of where things stand at the moment.
Honestly, the language model downstream will often compensate for some of those OCR errors. It understands enough of the gist that even if your input is only 75% accurate, the summary it produces may come out a bit better. That said, you may still get the occasional weird artifact—like a stray mention of “George” that has no context. It’s not always clear where those come from.
All of this was built around a framework called Griptape. We’re not positioning Griptape as the solution—it’s one of many agentic AI workflow frameworks out there. It worked well enough for this experiment, but it was easy enough to pick up and had more than enough built-in to get me where I needed to be.
Griptape is the framework that made this whole setup possible. It’s the glue that lets you snap the components together—kind of like Lego bricks (though maybe that’s a bad analogy–Legos don’t need glue. Fight the Kragle!).
In this workflow, we take the extracted content and generate summaries for each document. Then we push those forward to the next step: generating questions. These aren’t generic questions—they’re designed to probe the gaps, to ask questions that aren’t already answered in the summaries. A model creates those questions, which we then point back at the original documents rather than the summaries. That helps ensure we’re not propagating shallow answers through shallow inputs.
From there, we gather all the summaries and the newly generated answers, pair them with their originating questions, and hand the whole package off to Anthropic’s Sonnet 3.7 model. The prompt is simple: “Here’s everything—make me a research paper.” OK, not really, but it’s not much more magic than that. That last step leans on Sonnet’s large context window and inference quality.
“...if you’re interested in learning—in tinkering, running things locally, and really understanding the moving parts—this project offers a hands-on blueprint. It’s meant to be something others can follow, adapt, and build on.”
Dillon Roach
You could make every stage in this pipeline more complicated—there are packages out there that are robust and production-ready. I found several excellent ones halfway through building this. So, if your goal is a polished, production-grade pipeline, you’ve got options. But if you’re interested in learning—in tinkering, running things locally, and really understanding the moving parts—this project offers a hands-on blueprint. It’s meant to be something others can follow, adapt, and build on.
In terms of time and resource investment, it depends on how you measure. You could run this end-to-end in 20 minutes, no problem…OCR aside. However, I did spend quite a bit of time experimenting: batching strategies, alternate setups, different models. That kind of iterative tinkering adds overhead, but it also adds understanding. We ended up with a deeper perspective on tradeoffs at every point along the way.
Each decision adds to the library of learnings. Throughout the process, I bounced between a few different language models:
One other component worth mentioning is that I used TabbyAPI as the language model server backend and wrote a small client to make it easy to hot-swap models in and out of the pipeline. Behind the scenes, it’s all just cURL requests, and that pattern will be available for others to use, too.
“Deep research,” as a concept, is still evolving. The trend right now leans heavily on online scraping and aggregation, but for enterprises and researchers with rich internal data, a local, document-first approach offers more control, more security, and often more relevance. It will take longer than a simple vector-likeness lookup in RAG, but the results will be far more useful in many cases.
This project was about experimentation—about seeing how far we could push a local workflow quickly, using open tools, open models, and a healthy dose of curiosity. The result: a flexible, modular pipeline that generates end-to-end research summaries from your own PDFs without ever needing to hit the internet.
We’re continuing to evolve this work at Quansight. If you’re a researcher, engineer, or team looking to understand your own data better, or curious about how to integrate this kind of framework into your workflows, we’d love to talk.
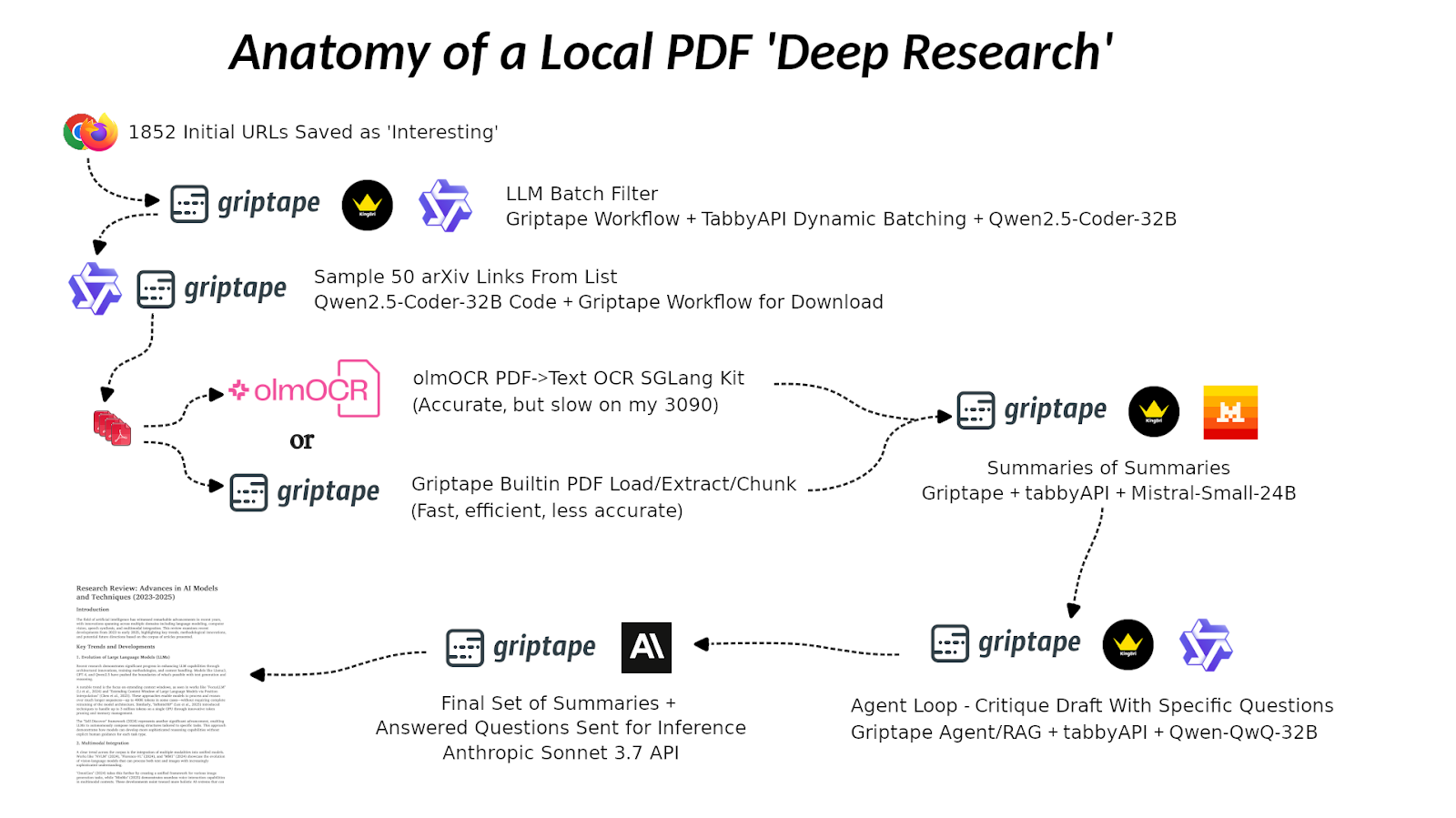
So yeah, that’s the gist of it. Any questions?




