2023 will be remembered as the year when AI and LLMs took the world by storm. PyTorch took center stage during this revolution due to the rise of torch.compile. The combination of having a fully flexible eager execution model, paired with a compiler with a rather flexible tracer that is able to understand complex Python programs semantically, has certainly been one of the core components fueling these advances.
In this post, we’ll go over different parts of the stack that make up torch.compile and different features that Quansight engineers have implemented this year, helping Meta engineers make torch.compile as fast, resilient, and flexible as it is today.
torch.compiletorch.compile‘s[1] value proposition is quite simple: Tag your model with @torch.compile, and your program will run faster.
This is quite an ambitious proposal. In a PyTorch model, you may have many different PyTorch operations scattered around your own code and other library code. Also, you may use external libraries like NumPy to perform some computations. Finally, you might use advanced Python constructions like generators or metaclasses to organize your code better. The implementation of models, and even more so modern ones, can be rather complex, so how does torch.compile achieve this?
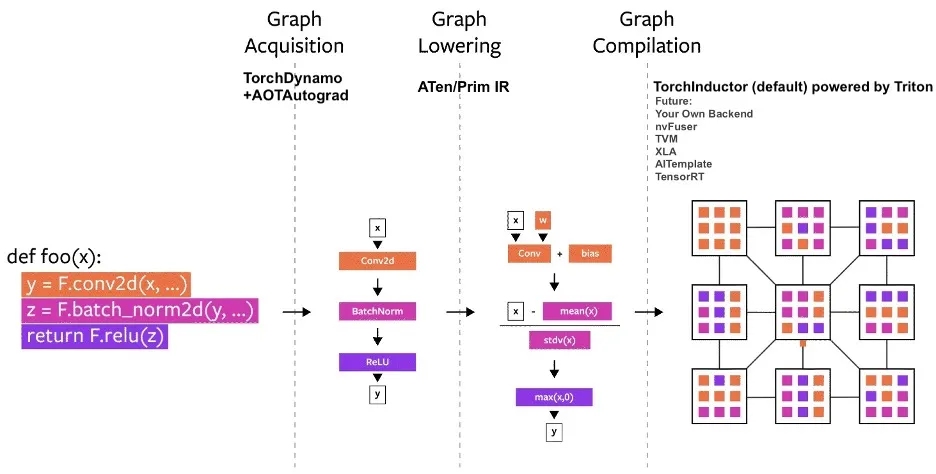
torch.compile follows a three-step pipeline:torch.compile, let’s delve into some of the most notable contributions that Quansight has made to these. Library Support Dynamo symbolically executes Python code and finds calls to PyTorch functions, and stores them in a graph. Now, there are many functions and external libraries that are not written in Python but are written as C-extensions of Python. As such, we cannot just simply expect Dynamo to be able to understand them. One line of work in Dynamo is to teach it how to handle new functions.
Quansight has helped to do so for three commonly used libraries:
torch.compile. For example, you can vmap over your NumPy program! torch.compile is implemented. Correctness Integrating many different subsystems into a large system is often quite difficult to do correctly, even more so when there is some global state. This is no different in Dynamo. Dynamo tries to simplify symbolic expressions, trying to see when a set of symbolic expressions (axioms) implies a new one. This is a very difficult problem in general, so PyTorch implements a number of hand-written rules to try to make this problem tractable. Quansight engineers implemented a system that, using a theorem prover, would mathematically prove that these simplifications are indeed mathematically sound. They also added a full subsystem to debug errors emanating from these, which tend to be particularly challenging to debug.
Indirect Indexing Advanced indexing of the form t[idx] where idx is a tensor of indices is a rather common pattern in PyTorch, used to implement pooling operations or just rearrange a tensor. This is also called indirect indexing, as the indices are not static but come from a tensor. Quansight engineers have implemented a number of compiler passes that optimize this pattern:
associative_scan that takes an arbitrary associative pointwise function to allow the implementation of Mamba and generic SSMs in pure Python via torch.compile. torch.compile generates Triton code when targeting the device="cuda". tl.reduce function that takes a lambda function with an associative operator as an input, and performs the reduction. This enabled the implementation of the Welford reduction discussed in the previous section. float32; they just support a lower-precision version called tf32. To compensate for this, CUTLASS engineers proposed a trick whereby, using 3 tf32 multiplications, one could get better accuracy than float32 and about a 2x speedup over the non-Tenor Core implementation. Quansight engineers implemented this trick natively in Triton. tl.associative_scan was implemented already accepting an associative operation as an input, but it had the limitation that this operation had to be a scalar operator. Quansight engineers generalized this to support operations that take multiple inputs and outputs to allow for the implementation of ops like torch.cummax. torch.compile has brought is the same PyTorch we have known for years, and work continues to maintain and improve these core systems. Feature development, performance optimization, and better engineering projects are still ongoing, with Quansight involved in a few key areas. Semi-Structured Sparsity This is a unique sparse layout that relies on hardware support. NVIDIA’s Sparse Tensor Cores support a fine-grained sparsity pattern where a contiguous block of 4 values has only two non-zero. We worked to integrate kernels from CUTLASS into PyTorch, as well as the APIs for compression/decompression of tensors for structured sparsity.
Inductor Support Several of these features have also been added to the torch.compile execution pathway by adding codegen templates to inductor. This allows the compiler to generate a bespoke kernel on the fly, including epilogue fusion for your models using semi-structured sparsity.
PyObject owning a reference to a reference counted C++ object; sometimes, the C++ object needs to outlive the Python object, and sometimes it will be passed back to Python, allowing it to be resurrected. Tensor objects implement the PyObject Preservation pattern to support all these scenarios while allowing properties like subclass information, and dynamic attributes to be preserved. Tensor objects have supported this, but new needs motivated applying the pattern to Storage objects (how we represent the memory blob backing a tensor). Our team worked on this feature. If you are interested, this is not specific to PyTorch, and this stand-alone repo demonstrates how the pattern can be applied anywhere. torch.compile implemented by Quansight engineers. We also presented two posters in the poster session, delving into the details of some of the features discussed above. torch.compile, whose development, as that of any compiler, tends to be a bit more complex in nature. That being said, we hope this post helps showcase the type of work that’s performed by our engineers.