"You will not be able to succeed as a company unless you leverage open source effectively.”
Dharhas Pothina, Quansight CTO
Are you tired of encountering issues when installing new Python packages, resulting in disruptions to your existing code and Jupyter notebooks? Have you ever uttered the phrase, “Well, it works on my computer,” to a colleague, indicating that the issue seems specific to their environment? If so, there is a promising solution. We are introducing an accessible and user-friendly open source tool that helps you to create and manage a collection of stable, reproducible, and version-controlled environments in the cloud or on your laptop.
conda-store comes from seeing the same problem from multiple clients and knowing there is a better way to solve it. If we make it an open source project, we can leverage the community and the problems that everyone has and build something applicable across many domains. Managing software environments is one of many organizations’ most significant pain points. Almost every organization we visit, big and small, has a problem with data science software environments.
If you have been using Python for some time, you likely already know the problem. Have you installed a Python package? Better yet, have you had to figure out how to install a Python package? Well, you’re not alone.
My background is in aerospace engineering. Initially, I wrote things in Fortran, Pearl, and Matlab. In 2008, I found Python. Below is the SciPy user mailing list from October 2008. I went there to ask for help to install NumPy. It was all new to me. As you can see, I’ve been doing this for a while, and even though Python is painful to install now, it is a lot better (but it isn’t much better).
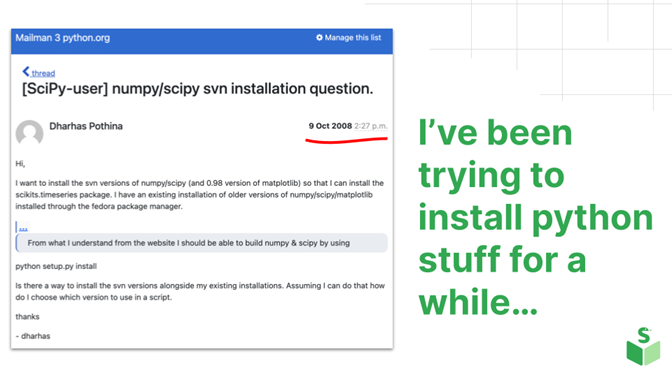
Have you ever written Python code that runs fine on your machine, then handed it over to your colleague, and they responded that nothing works? This scenario has frustrated me for many years, and now, since I finally work at a company that uses open source, I can do something about it.
We are benefactors of a massive community of libraries. When I started using Python in 2008, NumPy was the big thing. Today, NumPy is way down in the basement substructure below the data science foundation. The PyData stack, or the Scientific Python stack, is based on NumPy at the bottom, along with other foundational libraries. Then, you have the library specific to certain techniques, like statistics or network analysis. There are domain-specific and application-specific libraries.
This whole ecosystem moves very fast. It incorporates the latest research. It uses multiple languages and compilers, like Python or R codes. It might depend on Fortran, C++, or other languages, so this is not a single-language ecosystem like some large Java apps might be. It includes thousands of individual and corporate contributors.

I’ve met many people who don’t even know NumPy exists. They work in Pandas, Polars, statsmodels, Biopython, Astropy, or something else near the top. Open source is a vast ecosystem built collaboratively worldwide by thousands of people doing cool stuff.
Do you remember Sun Microsystems? We used to be able to take a binary from Solaris 1 and plop it into Solaris 8, and it would just work. Today, if you go from Pandas 1.5 to 1.53, maybe your stuff is okay, but use Pandas 2, and it “breaks.” Backward compatibility is not a thing with Python. The marvelous new stuff is fantastic, but it has issues.
Considering the sheer number of contributors, the number of languages involved, and the fact that everyone is trying to incorporate the latest research and cutting-edge ideas, in that case, this whole ecosystem is inherently not backward compatible. Backward compatibility, however, is seldom even an afterthought. That’s all about to change.
Data science, the whole scientific ecosystem, is designed to move fast. These environments are complicated to create, difficult to maintain, and even harder to share. You will see this a lot in most organizations. You have environments where you often hear this phrase: “It works on my machine.” This topic is one of the most common issues organizations face. Part of this is that data scientists, engineers, and developers often think of all these libraries as independent software tools and not as libraries.
A typical pattern for most people, especially on their native laptop or desktop, is to decide they need “a tool,” such as Python, a library like Pandas, or something similar, and they will download that software, install it, double-click something, or do something like a Pip or conda install. Then they’ll install Python and maybe Pandas, realizing later they want scikit-learn, and a month later, admit, “Oh, I think this project needs to use PyTorch,” and install PyTorch. Then, they recognize that they need a different version of their software for a new project. They’ll install that, and (this happens on laptops and desktops, but it can also happen on cloud servers) you eventually end up with this unique unicorn software environment that only works on that laptop or server.
Try to run it somewhere else or try to move it to another machine or move it into production if you have a research team or a team building a machine learning model–and now you want to take that machine learning model and move it into production–you now hit this issue of, “It works on my machine.” You can’t transfer it, so what do IT departments do? They dockerize everything.

Do you use requirements.txt or environments.yml? Do you work in both?
They each have problems, and both could be better. The state of the Python ecosystem for packaging could be better, but there are social, historical, and solid technical reasons for this. Python is a glue language that sticks to other languages. Because of this, we don’t just have personal packaging problems; we have all the packaging problems of Rust, C++, and everything else we depend on.

Python is the bane of Enterprise IT people. We want flexibility, the latest version of Pandas and Polars. The next version of PyTorch is pytorch.compile, allowing us to run our NumPy code on a GPU. We want that flexibility. We want to be able to do all that and more. The flip side is that reproducibility becomes a problem.
Here is typically what I’ve seen most people say:
We tend to agglomerate these environments over time, which become this unholy thing that, if you push it slightly, will fall over. You cannot recreate it because you did installations at various points in the past, and the condition of the internet and available packages differed at those times. Even if I have the requirements.txt or the environment.yml Conda, if I ran that six months ago and ran that same environment requirements.txt today, I would get a different set of packages.

Organizations tend to put everything in containers and ship the containers, which is a good reproducibility solution, except it’s only part of the solution. You often end up with the opposite situation. Usually, creating these containers and shipping things to production is laborious. It is slow and requires DevOps expertise and people with the proper permissions on infrastructure. You end up in this situation where the software used in the research environments is not available in the production system, and adding new software to the production systems can take months. In some cases, we have one client for whom it took a year to get a new version of a particular library onto that production system because of the change request required and the process of creating the containers and moving them into the production systems.
The issue is that the data science, artificial intelligence, and machine learning (AI/ML) worlds are moving fast. You cannot anticipate which software projects or packages you need to solve the problem. All these packages change continuously, and they get updated and have new features, which are critical to effectively moving into the future.
You could say, “We’re going to freeze all our software requirements at the beginning of the year, and everyone has to use these libraries.” That is a reasonable choice, and you will solve one problem. You’ll solve the problem of making things work in production. Still, you will severely hamper your competitive edge and the ability of your organization to use the latest technology (imagine a year ago, we didn’t have some of the machine learning and AI tools that we have even today).
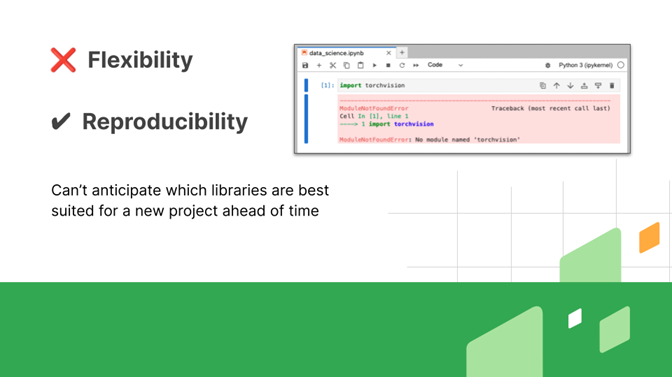
Have you ever started analyzing a new data set, and only after starting your project did you realize which packages you needed? Yeah, that’s the problem with the idea within companies that you can define all the software you need at the beginning of a project. A couple of years ago, we analyzed traffic data for a client, such as how many people turn left at this intersection and other similar data. There’s a Pandas extension that lets you identify routes. We didn’t know we needed that, but we needed to get it installed quickly and deployed.
Most organizations need help transitioning this issue between wanting flexibility and reproducibility. Historically, you could only choose one or the other.

One solution is conda, a cross-platform package manager. Implementing additional best practices on a personal laptop can resolve many data science software and environment issues. Unfortunately, these best practices are not well known, and their tooling needs to be improved when you move away from thinking of how an individual will handle software environments to how an organization or a team will handle them.
So, that’s why we came in and said, “Okay, we have a reasonable solution for an individual. How do we expand the solution for an organization or a team (and how do we enforce the best practices)?” You could enforce best practices by having a lot of training, teaching, and telling people what the best practices are, but that is fragile, and we wanted to make something more robust. Below are the three we recommend the most.
Always use an environment specification. We’ve had this problem. We were doing a project for a company around recognizing brand images in videos. For example, if you see in the video that there’s a bank’s logo, and you want a system to say, “Oh, the bank logo is in this video,” we found a good model built about eight months before the project, with the requirement.txt for it.
Once you have an environment specification, install your environment and create a lock-file. A lock-file contains the exact list of every package installed because you have the requirements.txt, including the hash, the architecture, and more.
Now, you have an environment, and you suddenly realize you’re using Pandas, but all your data is in Parque, so you need to install PyArrow. Go back, put it in your environment specification, and make a new environment. That is the safest way to recreate environments. Of course, there are more best practices. If you do some of these things, you can have reasonable reproducibility, but doing this consistently and remembering to do it all the time has required extra steps.

Now, where are you going to put the lock-files? Are you going to store them somewhere? How are you going to manage all of this? That’s what we’ve been building over the last couple of years. It’s a tool we call conda-store.
We’ve taken some of the existing best practices for the conda ecosystem. Tell us what you need, and we’ll ensure we follow all the best practices behind the scenes to provide you with a reproducible environment to share with others.
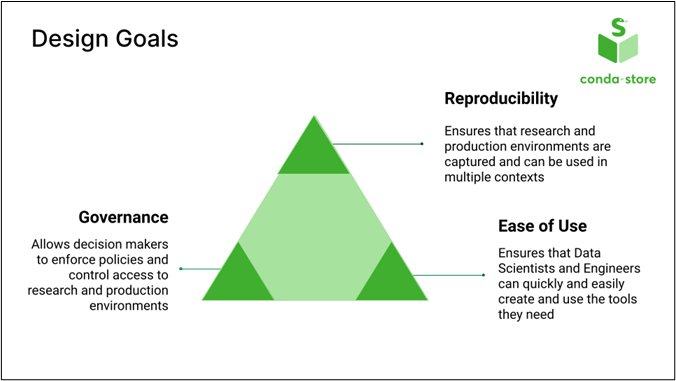
We must guarantee that your software environment is reproducible, fully captured, and usable in multiple contexts. We don’t want to say you must use it in a Docker image or container. That’s one of the contexts, but you might also want something lighter weight, so we want to capture the environment. You can also use it in the cloud, a local setting, and a research or production environment. We want to ensure it’s transportable across all those environments or contexts.
We want it to be easy to use. The data scientists, engineers, and software developers need to be able to quickly and easily create environments and install the software they need without going through a long process.
You might have governance issues in an organization to enforce policies or ensure that folks only install approved software. You might also have constraints on what software goes into production, and we want to enable a balance.
On one extreme, you have a wholly locked-down production environment, and adding packages to that environment rarely happens and involves an extensive, long change control process. Then, when they update the environment with the new packages, anyone dependent on the older ones is now done because that’s the latest production environment.
The other side I’ve seen is a free-for-all, where the data scientists and engineers can install whatever they want. Soon, it becomes a mess. No one knows what was installed for each project, and there’s no way to share. When sharing a project or algorithm, providing clear documentation on the tools and software versions is essential so others can easily replicate and run it.
Because of this, we’re trying to find a balance between Reproducibility, Ease of Use, and Governance.
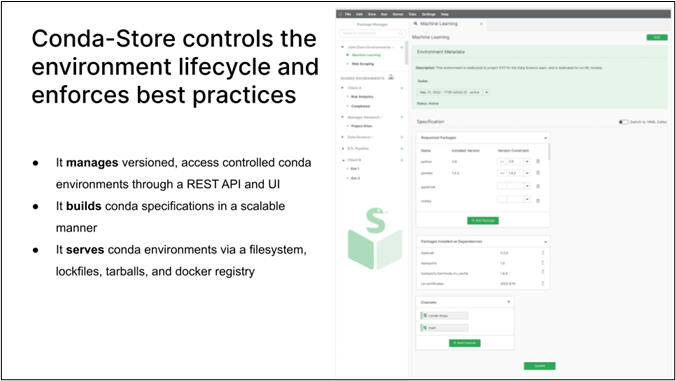
Essentially, conda-store controls the environment’s lifecycle (and enforces best practices). It manages environment specifications, builds those specifications in a scalable manner, and serves the environments via multiple contexts. conda-store runs as a server. There’s a Rest API in the UI, and then you can pull environments from it or have it build environments and place them in different locations.
First, the API and the UI enforce and guide you to best practices. Instead of you progressively adding packages and saying, “Okay, I need Pandas. Now I need scikit-learn. Now I need NumPy. Now I need PyTorch, etc.,” we give you an API and an interface where we clearly distinguish between the packages you’ve requested and the version constraints you’ve put on them.
Instead of you installing things individually, we continually build a specification and use these specifications to create an environment for you. You know what you specified, and then have an environment built from that. We can then distinguish between the requested packages and those installed as dependencies.

We enforce reproducibility by building lock-files and artifacts. To make reproducible packages, you need to know the exact hashes of every package installed and have a lock-file. It’s what you use when you build a Docker container. Anyone who’s started building environments ends up with a lock-file in whichever language they’re using.
End users want to specify something other than the specific lock-file. It’s too complicated. They want to say, “I want Pandas, I want scikit-learn, I want PyTorch.” So, we auto-generate the lock-file, re-version it, and auto-generate the build artifacts like the Docker containers and the tarballs, and we version all those things. On the one hand, we have the usability of letting people build things. On the other hand, we have the exact lock-files and artifacts required to go back and forth between versions of the environment.
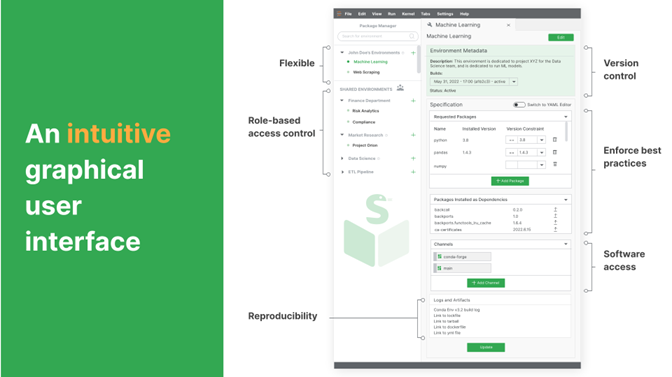
As stated, the conda-store UI tries to force you to use best practices. You give it an environment name, define your specification, and then it lists items installed as dependencies. It lists where it’s coming from and automatically creates a lock-file, a Docker image, and a TarGZ (you can unpack somewhere else). You’re divorcing your specification from the artifact. The artifact is an environment; you might want to run it locally, you might want to run it in the cloud, and you might want to ship it to someone else’s machine. We want those to be two separate issues.
We originally built this for use in the cloud, JupyterHub, and other platforms involving multiple people. Recently, we also got it working on a laptop.
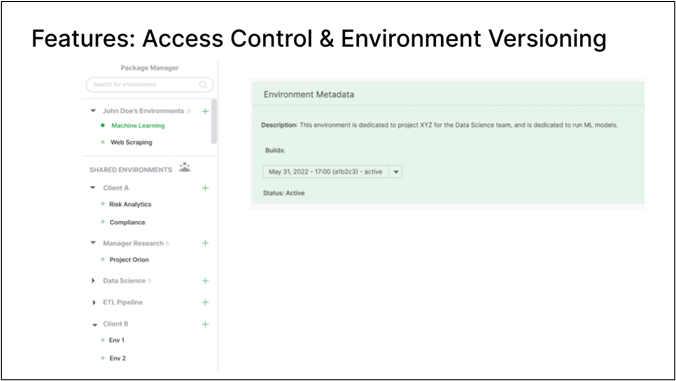
One of the most exciting benefits of conda-store is thinking about environments as a versioned thing. You have an environment, give it a name, provide it with metadata, and then we have a version of the entire environment. People think of versioning packages as having Pandas 1.4 or something, but here we have a collection of packages, and now we’re versioning it. Say you have a production data science environment or machine learning environment, and now, you can switch it to a different environment, an older version, giving you backward compatibility. If I add packages, it will create a new version from scratch. So you can move backward and forward through these environment versions, and since these have unique hashes, you can also embed the environment hash in your script or Jupyter Notebook. You now have control over the environment used for a particular project.
Additionally, the access control for conda-store involves multiple namespaces. For example, “John Doe” has environments for machine learning and web scraping. Additionally, there are shared environments for different groups within the organization. These shared environments can be read-only, allowing “John” to use them but not modify them. Alternatively, if “John” is a team lead, he may have permission to adjust these shared environments. This approach balances individuals’ ability to create necessary environments with management’s need for governance. Therefore, if “John Doe” creates an environment for an experiment, it’s recorded and can be migrated to a shared environment. All artifacts are available, ensuring that analyses can be rerun in the future using the same data environment and scripts.

We’ve been using this in production with multiple companies in the cloud, in more of a data science platform/JupyterHub-type setting, for about 2-3 years. The desktop version and Mac and Windows compatibility are (basically) bleeding-edge. You can now use this on your laptop or desktop, but it needs to be more production-ready before launching. But please use it!
I’ve been dealing with packaging and environments for years, and we shouldn’t have to worry about them. We should be able to install stuff and share things and not have to deal with, “Well, it works on my computer.”
This project is now part of the conda incubator, so it’s something we built and submitted, and it’s on its way to becoming an official part of conda through the incubator program. We would love it if you used it and gave feedback or helped us develop it.
The software’s website is conda.store and it is also on GitHub. If you need additional help, Quansight consults around conda-store; we can help you set it up and add features as needed. Find out more here.

”You can succeed with open source. Anytime you build internal proprietary software, you're taking on the software's maintenance and intellectual burden of that software on your organization. I encourage companies to push things back to the open source community as much as possible and only maintain a thin layer of internal software. When you can put new features into the upstream open source libraries versus trying to build them on your own, you will have access to a more extensive set of eyes and a larger set of (human) brain power. You will have stuff that's internal to your organization, and that’s your special sauce. That's how you'll be successful."
Dharhas Pothina, Quansight CTO



